
Editor’s Brief
OpenAI has released GPT-5.4, a model that bridges the gap between specialized coding performance and general-purpose reasoning. Positioned as the successor to the "robotic" GPT-5.3 Codex, this iteration introduces a 1-million-token context window, native computer-use capabilities, and a "Tool Search" feature that significantly reduces token overhead. For developers using the OpenClaw framework, GPT-5.4 represents a shift toward economic viability, offering high-tier agentic performance within a standard $20 monthly subscription.
Key Takeaways
- The "Human" Codex:** GPT-5.4 maintains the elite coding benchmarks of the 5.3 Codex (57.7% on SWE-Bench Pro) while drastically improving world knowledge and natural language communication, resolving the "unreadable" output issues of its predecessor.
- Massive Context & Tiered Pricing:** The expansion to a 1-million-token window allows for complex, multi-step agent tasks, though OpenAI has implemented a 2x billing rate for tokens exceeding the 270,000 mark.
- Native Computer Use:** Built-in support for Playwright and vision-based navigation allows the model to interact with desktop environments and web applications natively, rather than relying on brittle third-party wrappers.
- Efficiency via Tool Search:** A new dynamic tool-loading mechanism prevents "context stuffing" by allowing the model to search for and retrieve tool definitions only when needed, cutting token usage by nearly 47%.
- Economic Disruption:** By allowing subscription-based access via Codex rather than forcing expensive API-only usage (like Claude 4.6), OpenAI is positioning GPT-5.4 as the default choice for small-to-mid-sized development teams.
Introduction
The following content has been compiled by VIPSTAR, based on public information from X / social media. It is intended for reading and research purposes only.
Key Points
- It was around 2 AM, and I was just about to go to bed.
- Suddenly, GPT-5.4 was released.
Note
For any sections involving rules, benefits, or judgments, please refer to the original statements and the latest official information from Digital Life Katsik.
Editor’s Comment
The article titled “X Import: Digital Life Katsik – GPT-5.4 Midnight Release, the Perfectly Suited Model for OpenClaw Finally Arrives” comes from the X social platform, authored by Digital Life Katsik. From a content completeness perspective, the original text provides a high density of key information, particularly in terms of core conclusions and actionable recommendations. It was around 2 AM when I was just about to go to bed, and then GPT-5.4 was suddenly released. I got so excited that I couldn’t sleep at all. Seriously, this isn’t me being overly dramatic; it’s rare for me to use such an expression of excitement. The reason is that I’ve been waiting for the official release of GPT-5.3 or GPT-5.4 to serve as my preferred model for OpenClaw. The reasoning is quite straightforward: in the modern world, which has fundamentally been built on code over the past thirty years, everything we see about computers and the internet… For readers, its most direct value isn’t just “learning a new perspective,” but being able to quickly understand the conditions, boundaries, and potential costs behind that perspective. If we break down this content into verifiable statements, it includes at least the following aspects: It was around 2 AM when I was just about to go to bed; then GPT-5.4 was suddenly released. Among these statements, the conclusions are often the easiest to spread, but what truly determines their practicality is whether the underlying assumptions hold true, if the sample size is sufficient, and if the time frame matches. We recommend that readers, when referencing such information, prioritize verifying data sources, publication times, and any differences in platform environments to avoid mistaking “contextual experience” for “universal rules.” From an industry impact perspective, this type of content typically exerts a short-term guiding influence on product strategies, operational rhythms, and resource allocation, especially in themes related to AI, development tools, growth, and monetization. From the editor’s viewpoint, we are more concerned with whether it can withstand subsequent factual tests: 1) Can the results be replicated? 2) Is the method transferable? 3) Are the costs sustainable? The source is x.com, and we suggest readers consider this as one of several inputs for decision-making rather than a sole basis. Finally, here’s a practical suggestion: If you plan to act on this information, start with a small-scale test and gradually increase your investment based on feedback. If the original content involves profits, policies, compliance, or platform rules, refer to the latest official announcements and have a rollback plan in place. The purpose of re-posting is to enhance the efficiency of information circulation, but the true value of content is realized through secondary judgment and localized practice. Based on this principle, our accompanying editorial comments will continuously emphasize verifiability, boundary awareness, and risk control to help you transform “information seen” into “actionable knowledge.”
It was around 2 AM, and I was just about to go to bed.
Then, GPT-5.4 was suddenly released.
*Figure 1: Accompanying Image*
I got so excited that I couldn’t sleep at all.
Really, this isn’t me being overly dramatic. I rarely use phrases like “too excited to sleep.”
The reason is that I’ve been waiting for the official release of GPT-5.3 or GPT-5.4 to serve as the primary model for my OpenClaw project.
The reasoning is quite straightforward: in the modern world, which has fundamentally evolved over the past thirty years, everything we see about computers and the internet is built on a foundation of code.
So you can understand that coding ability often represents one strong leg of an Agent’s capabilities.
In my view, an excellent base model for an Agent generally needs to excel in three areas:
Coding ability, world knowledge, and multimodal understanding.
When all three are state-of-the-art (SOTA), you’re almost certainly dealing with the best Agent model. Of course, another crucial factor is cost.
In the past, Claude Opus 4.6 was practically synonymous with Agent models because it excelled in coding and world knowledge. Although its multimodal capabilities weren’t as strong as Seed 2.0 or Gemini 3.1 Pro, they were sufficient for many scenarios since current Agents don’t interact much with the physical world—that’s more in the realm of embodied intelligence.
GPT-5.3-Codex, which I used to love, had exceptional coding ability and was incredibly precise when executing tasks.
However, the biggest issue was that it was a specialized programming model. Its world knowledge was terrible, even worse than GPT-5.2. So, OpenAI had no choice but to release it with the Codex suffix to compete with Claude.
So you can see…
In terms of planning capabilities, it is completely outmatched by Claude Opus 4.6. However, the biggest issue is actually due to its lack of world knowledge, which causes a lot of problems.
It speaks in gibberish; the things it says are really hard for me to understand. I’m not a programmer by training, and reading what it writes is genuinely very challenging.
For example, I asked it to review one of my AI trend website projects, mainly to check my documentation standards and the entire codebase.
Then, the document this guy wrote… I mean…

Compare it with what Claude Opus 4.6 wrote.

The difference should be obvious…
Because this thing doesn’t speak human language and lacks world knowledge, it’s fine to use it within Codex, but if you integrate it into your OpenClaw as the default model, you’ll realize what a disaster it is. This guy sounds so inhuman that I feel like punching him when he talks.
So, I tried it once and immediately abandoned it. In my OpenClaw, I still use Claude Opus 4.6 and Sonnet 4.6 for scene calls.
Why am I looking forward to GPT-5.4?
Because, while Claude is great in every way, it’s just too expensive!!!
It’s really, really expensive!!!!
And because of the clueless Anthropic, they’ve made OpenCla… (the text seems to be cut off here)
W went crazy, so the quota I subscribed to for Claude’s Max Plan can only be used on Claude Code and not at all for OpenClaw. If you want to use it on OpenClaw, you have to directly input the API Key.
However, everyone knows how expensive Claude’s API is; it’s something our broke team simply can’t afford. It might work for small-scale usage, but large-scale use would bankrupt the company.
There used to be another way: using a reverse proxy to route Claude’s quota from Google’s Antigravity through a plugin and then pass it to OpenClaw.
But later, Google started suspending accounts in large numbers, making this method unusable.
During the New Year, my Google account was also suspended, forcing me to use AI to write a heartfelt and tearful email to Google.
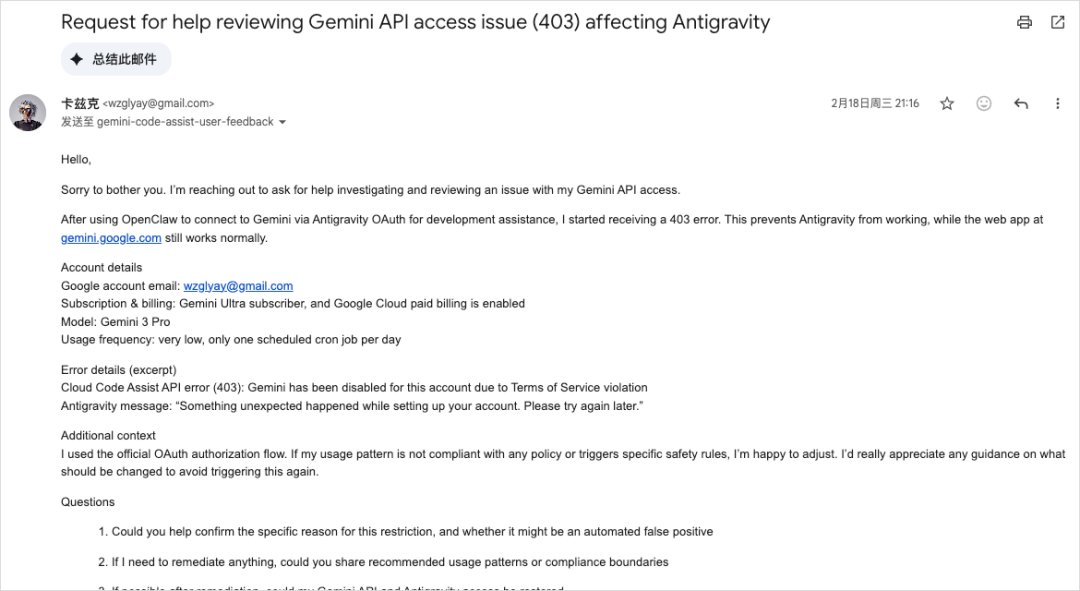
I said I was wrong and that it would never happen again.
Only then did Google unblock my account, but the reverse proxy method is definitely out of the question now.
OpenAI, on the other hand, took a different approach. When Claude started aggressively suspending OpenCode accounts, OpenAI stepped up and declared that they wouldn’t do any suspensions, encouraging everyone to use their services freely.

This is the only one among the Big Three that supports using third-party tools to call on Codex’s quota.
The same goes for OpenClaw. It’s one of the few top-tier models that can be accessed directly through a login, while others require an API.
Really, OpenAI has been incredibly generous this time around.
They’ve also been ramping up the quota for Codex.

So, while Claude is great to use in OpenClaw, it can only be used via API and that gets quite expensive since you can’t use the subscription quota.
OpenAI’s models, on the other hand, do allow for the use of subscription quotas, but GPT-5.2 doesn’t handle code well, and GPT-5.3-Codex doesn’t understand human language properly.
You see how awkward that is?
But now, here comes GPT-5.4!
Finally, it fills in the gaps!
It matches GPT-5.3-Codex in coding ability, surpasses GPT-5.2 in world knowledge, and you can use your subscription quota with it. For just $20, you get an incredibly smooth experience.
Tell me, if this isn’t the perfect model for OpenClaw, who is? Hmm?
Starting today, everyone using OpenClaw should set their default model to…
Switch to GPT-5.4, really, trust me.
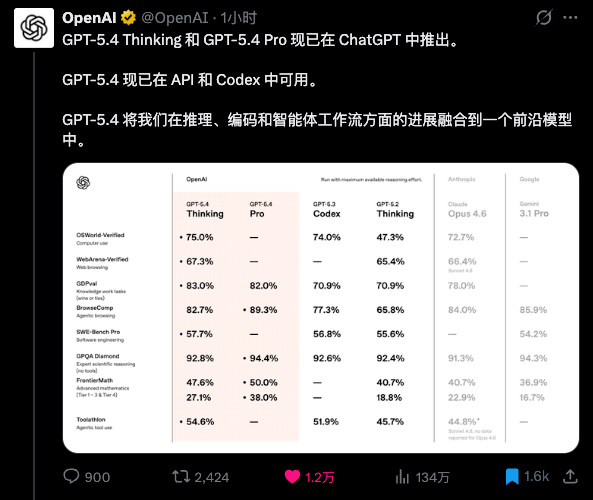
Back to GPT-5.4, as usual, let’s start with the benchmarks.
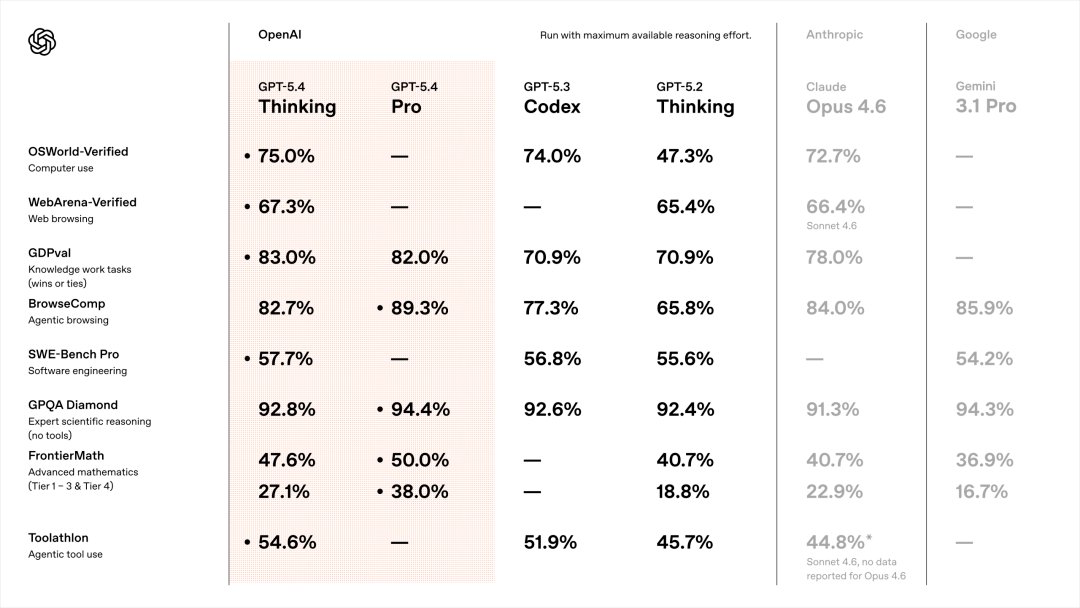
It’s really satisfying.
Let’s look at the most crucial ones first.
GDPval: 83.0%
This measures AI performance in real-world tasks, covering knowledge work across 44 professions including finance and law.
GPT-5.4 Thinking scored 83.0%, Claude Opus 4.6 scored 78.0%, and GPT-5.3 Codex scored 70.9%.
In real business scenarios, GPT-5.4 isn’t just good at writing code; it can also discuss business, finance, law, and various professional topics with you.
And it does so in human language, not gibberish.
SWE-Bench Pro: 57.7%
This measures AI’s ability to solve real software engineering problems, not just in Python but across four programming languages.
GPT-5.4 Thinking scored 57.7%, while GPT-5.3 Codex scored 56.8%.
They are basically on par.
This is exactly what I wanted to see.
GPT-5.4 maintains the coding capabilities of GPT-5.3 Codex and also improves its world knowledge.
The same goes for OSWorld-Verified, which scored 75.0%. This measures AI’s ability to operate a computer, such as using a mouse, keyboard, switching between applications, and completing various tasks.
GPT-5.4 Thinking scored 75.0%, surpassing Claude Opus 4.6’s 72.7% and maintaining parity with GPT-5.3-Codex.
Moreover, the speed at which GPT-5.4 operates a computer is incredibly fast.
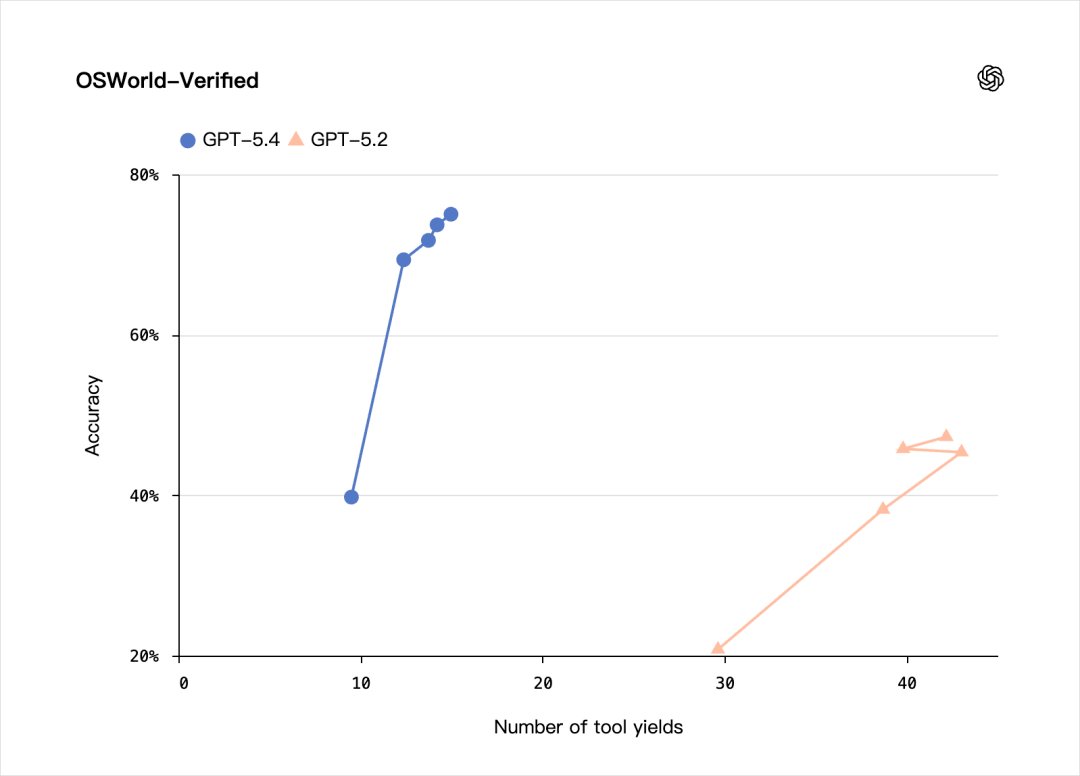
Watch this video without acceleration to get a clearer understanding.
ToolAthlon: 54.6%
This measures the AI’s ability to use tools, which is one of the core indicators of an agent’s capabilities.
GPT-5.4 Thinking scored 54.6%, while Claude Sonnet 4.6 scored 44.8%.
There’s nearly a 10-point difference.
As for academic knowledge, it can’t compare to GPT-5.3-codex because OpenAI is aware of this and didn’t even run the test at that time.
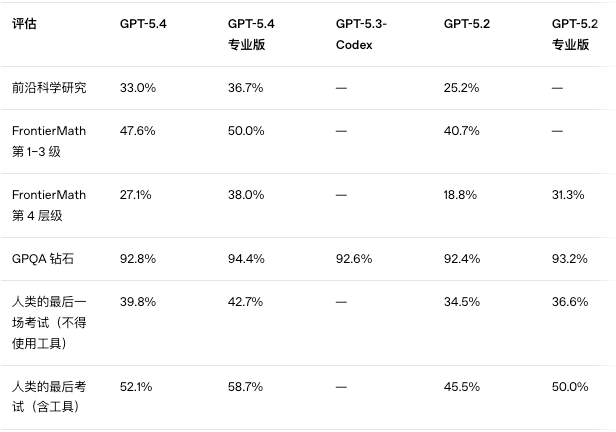
In simpler terms, it means:
GPT-5.4 = GPT-5.3 Codex’s coding ability + world knowledge surpassing GPT-5.2 + enhanced tool usage capability + extremely affordable codex quota.
When you combine these four aspects, you get a perfect OpenClaw base model.
Additionally, there are several excellent feature updates:
- A 1 million token context window.
This is a significant upgrade for GPT-5.4.
Previously, GPT-5.3 had a context window of 400,000 tokens, and GPT-5.4 has more than doubled this to 1 million tokens.
This is crucial for agents because they need to maintain an understanding of the entire task context while executing tasks. For example,
If the context window is not large enough, the Agent may start to forget things as it works, and won’t remember what was mentioned earlier.
One million tokens are basically sufficient to handle most Agent tasks.
Of course, OpenAI isn’t foolish; they state that after 270,000 tokens, your quota will be counted as double.

However, because the Codex quota is so generous, even doubling it is still manageable.
1. Native computing capabilities.
This is another major selling point of GPT-5.4.
OpenAI claims that GPT-5.4 is their first mainline model with built-in native computing capabilities.
It excels at writing code to manipulate computers using libraries like Playwright and can also issue mouse and keyboard commands based on screenshots.
In other words, it combines coding and visual processing. I feel that once this feature is integrated, it will truly allow for direct visual control of most software on your computer, which is really exciting.
Based on this, they have released a new skill called `playwright-interactive`.
This allows Codex to debug Web and Electron applications using both code and visual methods simultaneously.
You can find the link [here](#), where you can install it yourself.
https://github.com/openai/skills/tree/main/skills/.curated/playwright-interactive
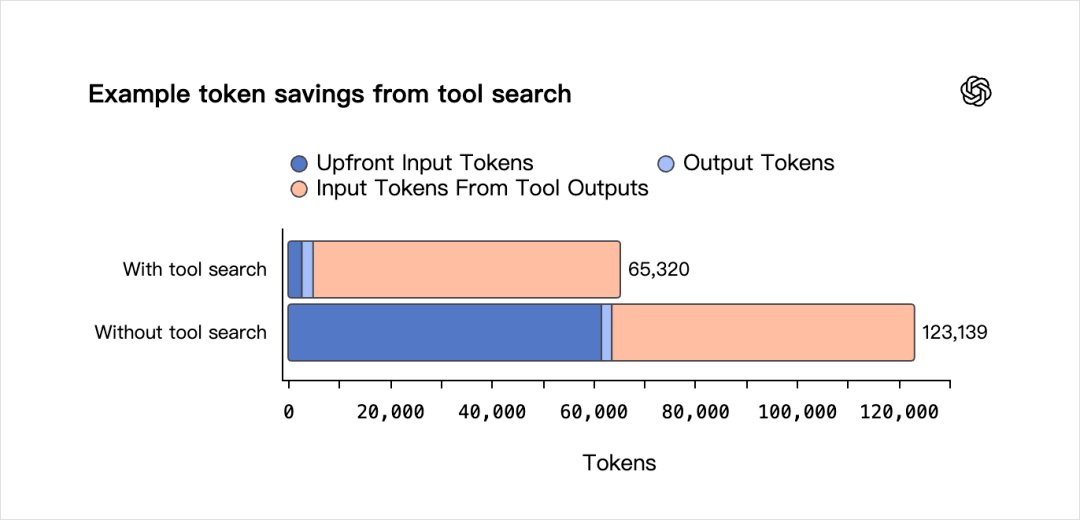
- Tool search support has been added.
In the past, when a model was provided with tools, all tool definitions were included in the prompt beforehand.
For systems with a large number of tools, this could add thousands or even tens of thousands of tokens to each request, which is often meaningless. This unnecessarily increases costs, slows down responses, and fills the context with information that the model may never use.
To address this, they have now added tool search support. GPT-5.4 no longer receives complete tool definitions directly but instead gets a lightweight list of available tools along with a tool search function.
When the model needs to use a specific tool, it can look up the tool’s definition and append it to the conversation at that moment.
This approach is similar to the progressive disclosure method used in Skills. The goal is simple: to optimize context engineering.
After testing internally, OpenAI found that the tool search configuration reduces overall token usage by 47% while maintaining the same accuracy. This is a significant improvement.
GPT-5.4 Thinking is roughly as described above.
This time, they also released GPT-5.4 Pro, which I won’t go into detail about. Essentially, everything is more powerful, but for most people, it’s too expensive and not very practical, costing $200.
Sure, here is the translation:
—
Only Pro members can use it.
It’s still worth mentioning the overall API pricing, even though most users will likely opt for the subscription plan.
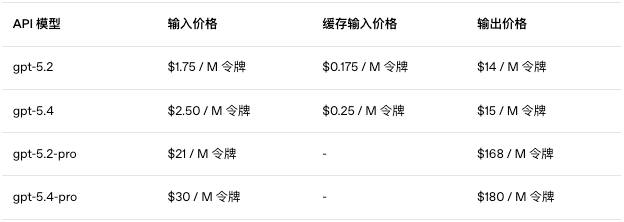
Compared to GPT-5.2, the price has increased, but it is still significantly cheaper than Claude Opus 4.6. The price for Claude Opus 4.6 is $5/$25 per million tokens (input/output), while GPT-5.4 costs only half as much.
ChatGPT is now live.
Codex is also supported, and I had a brief experience with it myself.
The first thing that struck me was the refreshingly human-like responses…
For example, when I asked it to download a video from the OpenAI website, its response was: “This is the most annoying task,” and “It saves both of us from Cloudflare’s lifespan drain”…
—
I hope this translation meets your needs!

And this one.
Really, I can actually understand the output from Codex…
The design of the front end has made some nice progress, but it still doesn’t match up to Opus 4.6 and Gemini.

I did a rough test of the writing, and it still has that peculiar tendency to use parallel sentences in a somewhat bizarre way.
Quite strange.
Then, it’s a bit disappointing that I waited until around 6 AM, but OpenClaw’s current method of logging in with Codex still doesn’t support GPT-5.4.
This means I still haven’t had the chance to test GPT-5.4 on crayfish.
Sure, here is the translation:
—
Effect.
However, I think today’s update will support it.
This is because many users in the community have been urging for it, and early adopters generally report very positive results.
I’m eagerly waiting for the support; I can hardly wait anymore.
Another exciting night ahead.
If you’re using OpenClaw, remember to switch the default model to GPT-5.4 once it’s supported.
If you haven’t tried OpenClaw yet, now is a great time to start.
After all, with the divine GPT-5.4 model, the experience will only be better.
The year 2026 is truly insane.
—
Source
Author: Digital Life Khazix
Publish Date: March 6, 2026, 11:10 AM
Source: Original Post Link
Editorial Comment
The tech industry has a love-hate relationship with the "midnight drop," but the release of GPT-5.4 feels less like a marketing stunt and more like a necessary course correction. For those of us tracking the trajectory of autonomous agents, the last year has been a frustrating exercise in compromise. You either used Claude Opus 4.6—which is brilliant but will bankrupt a small startup via API costs—or you wrestled with GPT-5.3 Codex, a model that could write functional Python in its sleep but spoke in a dialect of "technical gibberish" that made debugging a nightmare.
GPT-5.4 is OpenAI’s attempt to end that compromise. As a senior editor who has seen dozens of "SOTA" claims fall flat upon actual implementation, what strikes me here isn't just the raw benchmarks—though an 83% GDPval is nothing to scoff at. It’s the focus on the "quality of life" for the developer. The source text highlights a visceral pain point: the previous Codex model didn't "speak human." When an agent fails at 3:00 AM, you don't want a wall of esoteric symbols; you want a model that can explain, in plain English, why the Cloudflare bypass failed.
The integration with OpenClaw is the real story here. We are moving away from the era of "chatbot as a toy" and into "model as an operating system." The introduction of native computer use—specifically the `playwright-interactive` skill—suggests that OpenAI is no longer content with being a text box. They want to be the driver. By allowing the model to "see" the screen and "click" buttons natively, they are bypassing the latency and fragility of the "wrapper" economy. If GPT-5.4 can truly handle Electron apps and web debugging with the fluidity shown in the early demos, the barrier to entry for complex automation has just dropped significantly.
However, we need to talk about the "Tool Search" feature, as it’s the most underrated part of this update. In previous iterations, if you wanted an agent to have access to twenty different tools, you had to shove the definitions for all twenty into every single prompt. It was a massive waste of context and money. GPT-5.4’s ability to "search" for the right tool definition on the fly and only load it when necessary is a sophisticated bit of prompt engineering baked into the architecture. A 47% reduction in token usage isn't just a technical win; it’s a direct subsidy to the developer's bottom line.
Then there is the 1-million-token context window. While the headline number is impressive, the "2x billing after 270k" caveat is a classic OpenAI move—giving with one hand and taking with the other. It prevents the model from being a "free" dumping ground for entire codebases, but for the specific needs of OpenClaw users, it provides enough breathing room to maintain "state" over long, complex tasks without the agent "forgetting" the original goal.
Is it the "perfect" model? In 2026, perfection is a moving target. But by aligning the economic model (subscription access) with high-end agentic capabilities (native computer use and human-readable logs), OpenAI has effectively cornered the "prosumer" developer market. Claude 4.6 might still hold the edge in creative nuance or specific front-end aesthetics, but for the person building a fleet of agents to manage a business, the math now heavily favors GPT-5.4. It’s a pragmatic, powerful release that prioritizes utility over hype, and in this climate, that’s exactly what the market needs.